
可观测性工具。
Phoenix (Arize)
1. 介绍
为 RAG 管道建立基线通常不难,但要将其增强以适用于生产环境并确保响应质量几乎总是很困难。当有大量选项可供选择时,为 RAG 选择正确的工具和参数本身就可能具有挑战性。本教程分享了一个稳健的工作流程,用于在构建 RAG 并确保其质量时做出正确的选择。
本文介绍了如何结合使用多个开源库来评估、可视化和分析您的 RAG。我们将使用
- Ragas 用于合成测试数据生成和评估
- Arize AI 的 Phoenix 用于跟踪、可视化和聚类分析
- LlamaIndex 用于构建 RAG 管道
为了本文的目的,我们将使用 arXiv 上关于提示工程的论文数据来构建 RAG 管道。
ℹ️ 此笔记本需要一个 OpenAI API 密钥。
2. 安装依赖并导入库
运行下面的单元格以安装 Git LFS,我们用它来下载我们的数据集。
安装并导入 Python 依赖项。
!pip install "ragas<0.1.1" pypdf arize-phoenix "openinference-instrumentation-llama-index<1.0.0" "llama-index<0.10.0" pandas
import pandas as pd
# Display the complete contents of DataFrame cells.
pd.set_option("display.max_colwidth", None)
3. 配置您的 OpenAI API 密钥
如果您的 OpenAI API 密钥尚未设置为环境变量,请在此处设置。
import os
from getpass import getpass
import openai
if not (openai_api_key := os.getenv("OPENAI_API_KEY")):
openai_api_key = getpass("🔑 Enter your OpenAI API key: ")
openai.api_key = openai_api_key
os.environ["OPENAI_API_KEY"] = openai_api_key
4. 生成您的合成测试数据集
为评估策划一个黄金测试数据集可能是一个漫长、乏味且昂贵的过程,这并不实用——尤其是在刚开始或数据源不断变化时。这个问题可以通过综合生成高质量的数据点来解决,然后由开发人员进行验证。这可以将策划测试数据的时间和精力减少 90%。
运行下面的单元格,从 arXiv 下载 PDF 格式的提示工程论文数据集,并使用 LlamaIndex 读取这些文档。
from llama_index import SimpleDirectoryReader
dir_path = "./prompt-engineering-papers"
reader = SimpleDirectoryReader(dir_path, num_files_limit=2)
documents = reader.load_data()
一个理想的测试数据集应该包含高质量、多样化的数据点,这些数据点与生产环境中观察到的分布相似。Ragas 使用一种独特的基于演化的合成数据生成范式来生成最高质量的问题,同时也确保了生成问题的多样性。Ragas 默认在底层使用 OpenAI 模型,但您也可以自由选择任何您喜欢的模型。让我们使用 Ragas 生成 100 个数据点。
from ragas.testset import TestsetGenerator
from langchain_openai import ChatOpenAI
from ragas.embeddings import OpenAIEmbeddings
import openai
TEST_SIZE = 25
# generator with openai models
generator_llm = ChatOpenAI(model="gpt-4o-mini")
critic_llm = ChatOpenAI(model="gpt-4o")
openai_client = openai.OpenAI()
embeddings = OpenAIEmbeddings(client=openai_client)
generator = TestsetGenerator.from_langchain(generator_llm, critic_llm, embeddings)
# generate testset
testset = generator.generate_with_llamaindex_docs(documents, test_size=TEST_SIZE)
test_df = testset.to_pandas()
test_df.head()
您可以根据需要自由更改问题类型的分布。既然我们的测试数据集已经准备好了,让我们继续使用 LlamaIndex 构建一个简单的 RAG 管道。
5. 使用 LlamaIndex 构建您的 RAG 应用
LlamaIndex 是一个易于使用且灵活的框架,用于构建 RAG 应用程序。为简单起见,我们使用默认的 LLM (gpt-3.5-turbo) 和嵌入模型 (openai-ada-2)。
在后台启动 Phoenix 并对您的 LlamaIndex 应用程序进行检测,以便您的 OpenInference 跨度和跟踪被发送到 Phoenix 并由其收集。OpenInference 是一个构建在 OpenTelemetry 之上的开放标准,用于捕获和存储 LLM 应用程序的执行过程。它被设计为一种遥测数据类别,用于理解 LLM 的执行以及周围的应用程序上下文,例如从向量存储中检索和使用外部工具(如搜索引擎或 API)。
import phoenix as px
from llama_index import set_global_handler
session = px.launch_app()
set_global_handler("arize_phoenix")
构建您的查询引擎。
from llama_index.core import VectorStoreIndex, ServiceContext
from llama_index.embeddings.openai import OpenAIEmbedding
def build_query_engine(documents):
vector_index = VectorStoreIndex.from_documents(
documents,
service_context=ServiceContext.from_defaults(chunk_size=512),
embed_model=OpenAIEmbedding(),
)
query_engine = vector_index.as_query_engine(similarity_top_k=2)
return query_engine
query_engine = build_query_engine(documents)
如果您检查 Phoenix,您应该能看到在索引语料库数据时产生的嵌入跨度。导出并将这些嵌入保存到一个 DataFrame 中,以便稍后在本笔记本中进行可视化。
from phoenix.trace.dsl import SpanQuery
client = px.Client()
corpus_df = px.Client().query_spans(
SpanQuery().explode(
"embedding.embeddings",
text="embedding.text",
vector="embedding.vector",
)
)
corpus_df.head()
重新启动 Phoenix 以清除累积的跟踪。
6. 评估您的 LLM 应用
Ragas 提供了一份全面的指标列表,可用于从组件层面和端到端两个角度评估 RAG 管道。
要使用 Ragas,我们首先要构建一个评估数据集,该数据集由问题、生成的答案、检索到的上下文和真实答案(给定问题的实际期望答案)组成。
from datasets import Dataset
from tqdm.auto import tqdm
import pandas as pd
def generate_response(query_engine, question):
response = query_engine.query(question)
return {
"answer": response.response,
"contexts": [c.node.get_content() for c in response.source_nodes],
}
def generate_ragas_dataset(query_engine, test_df):
test_questions = test_df["question"].values
responses = [generate_response(query_engine, q) for q in tqdm(test_questions)]
dataset_dict = {
"question": test_questions,
"answer": [response["answer"] for response in responses],
"contexts": [response["contexts"] for response in responses],
"ground_truth": test_df["ground_truth"].values.tolist(),
}
ds = Dataset.from_dict(dataset_dict)
return ds
ragas_eval_dataset = generate_ragas_dataset(query_engine, test_df)
ragas_evals_df = pd.DataFrame(ragas_eval_dataset)
ragas_evals_df.head()
查看 Phoenix 以查看您的 LlamaIndex 应用程序跟踪。
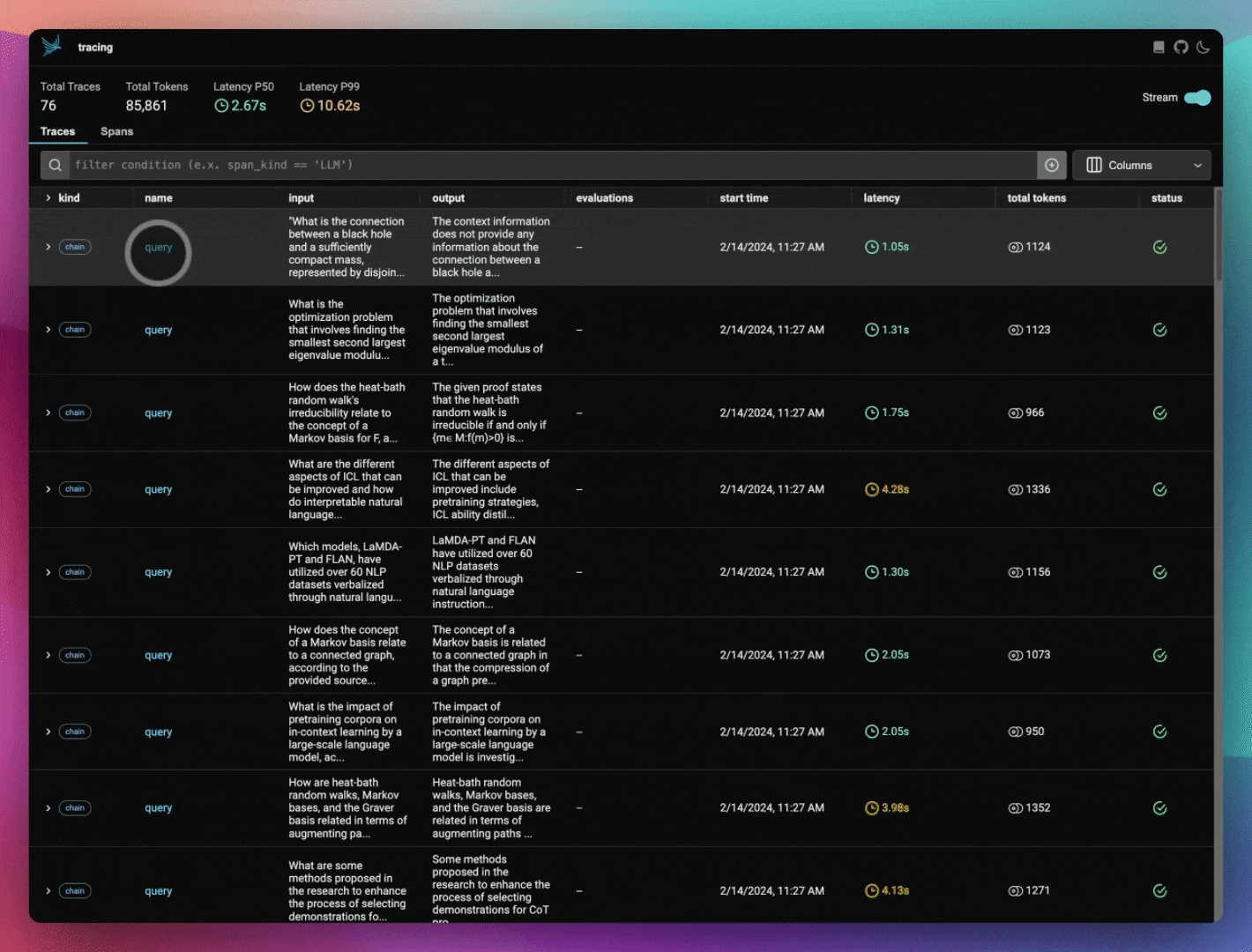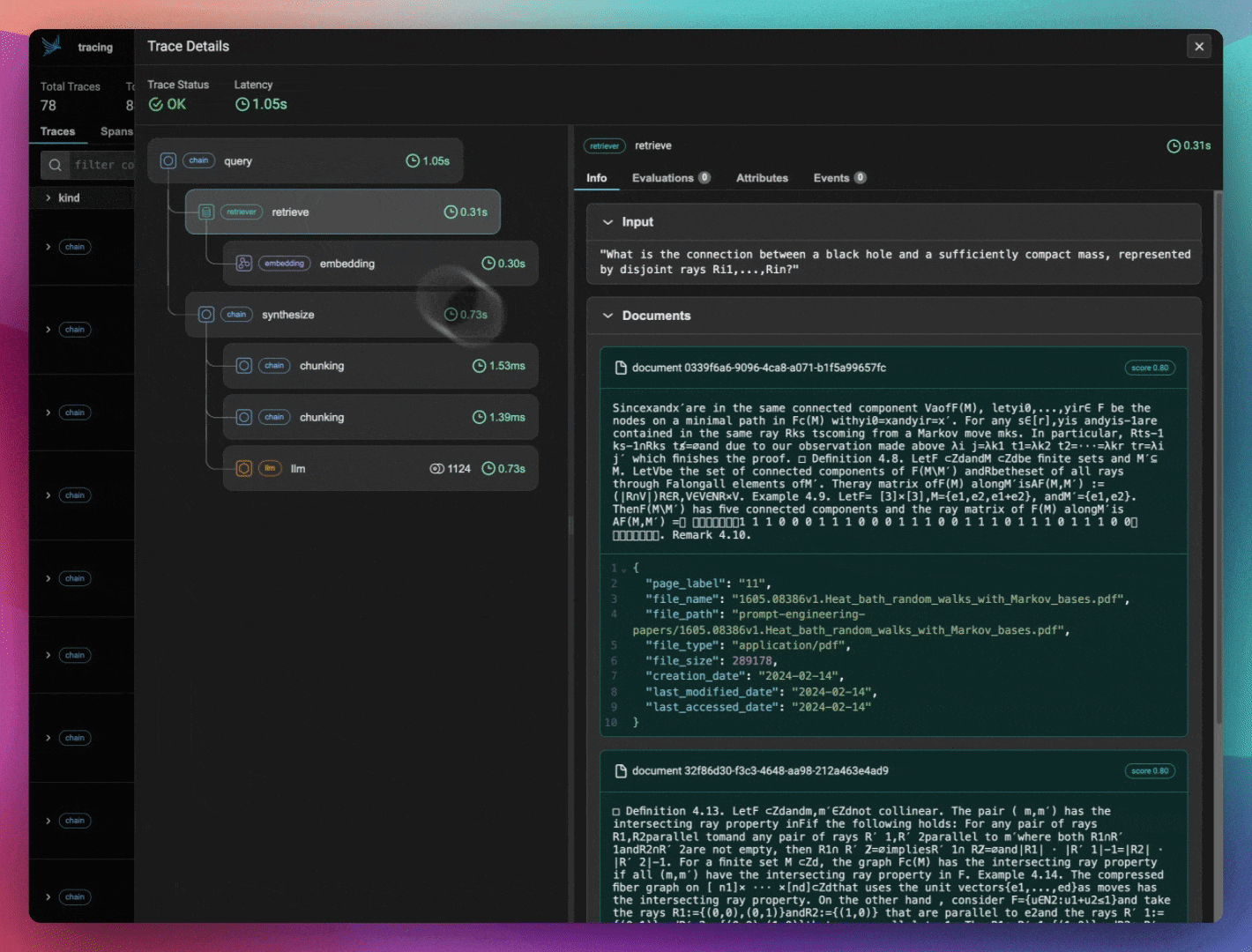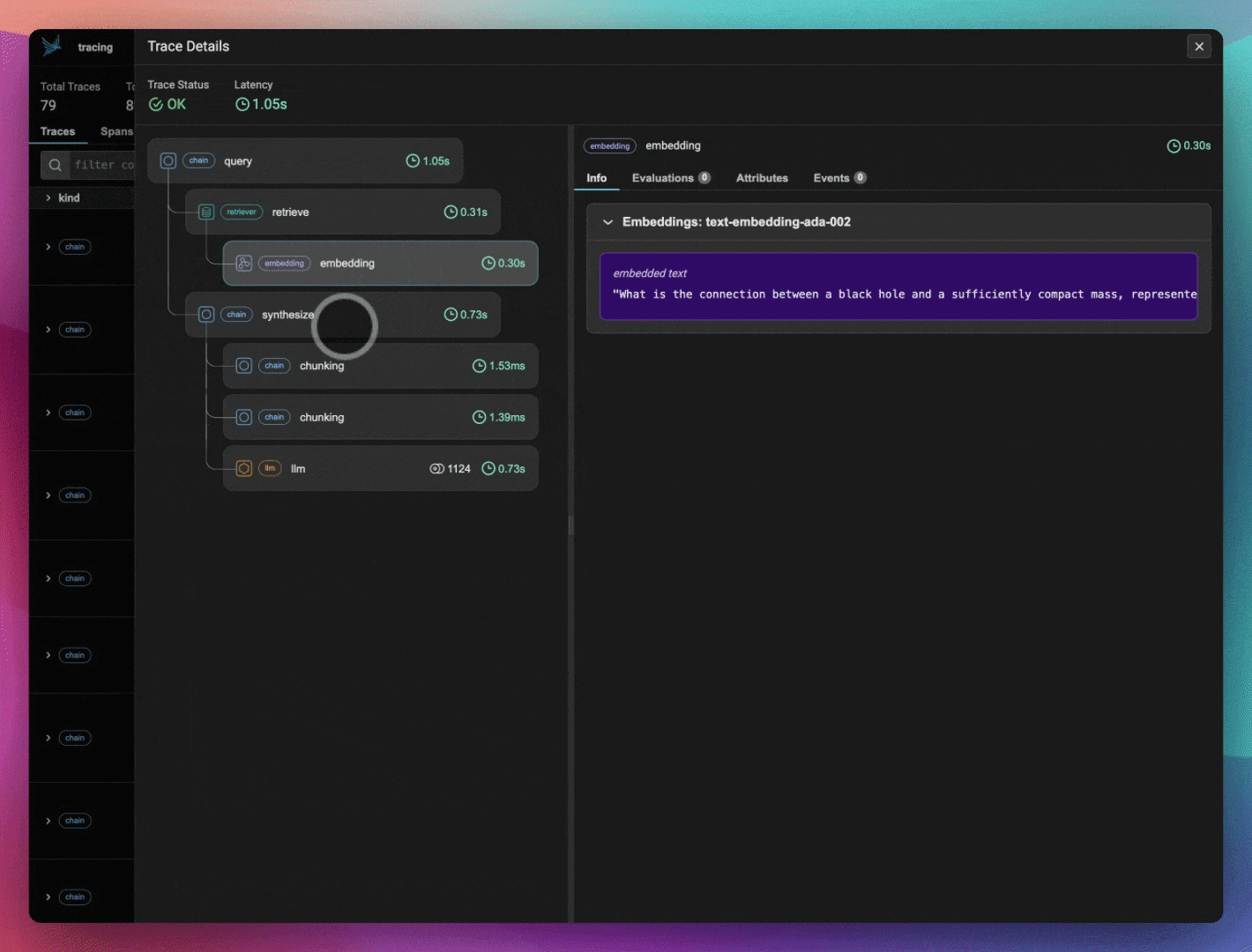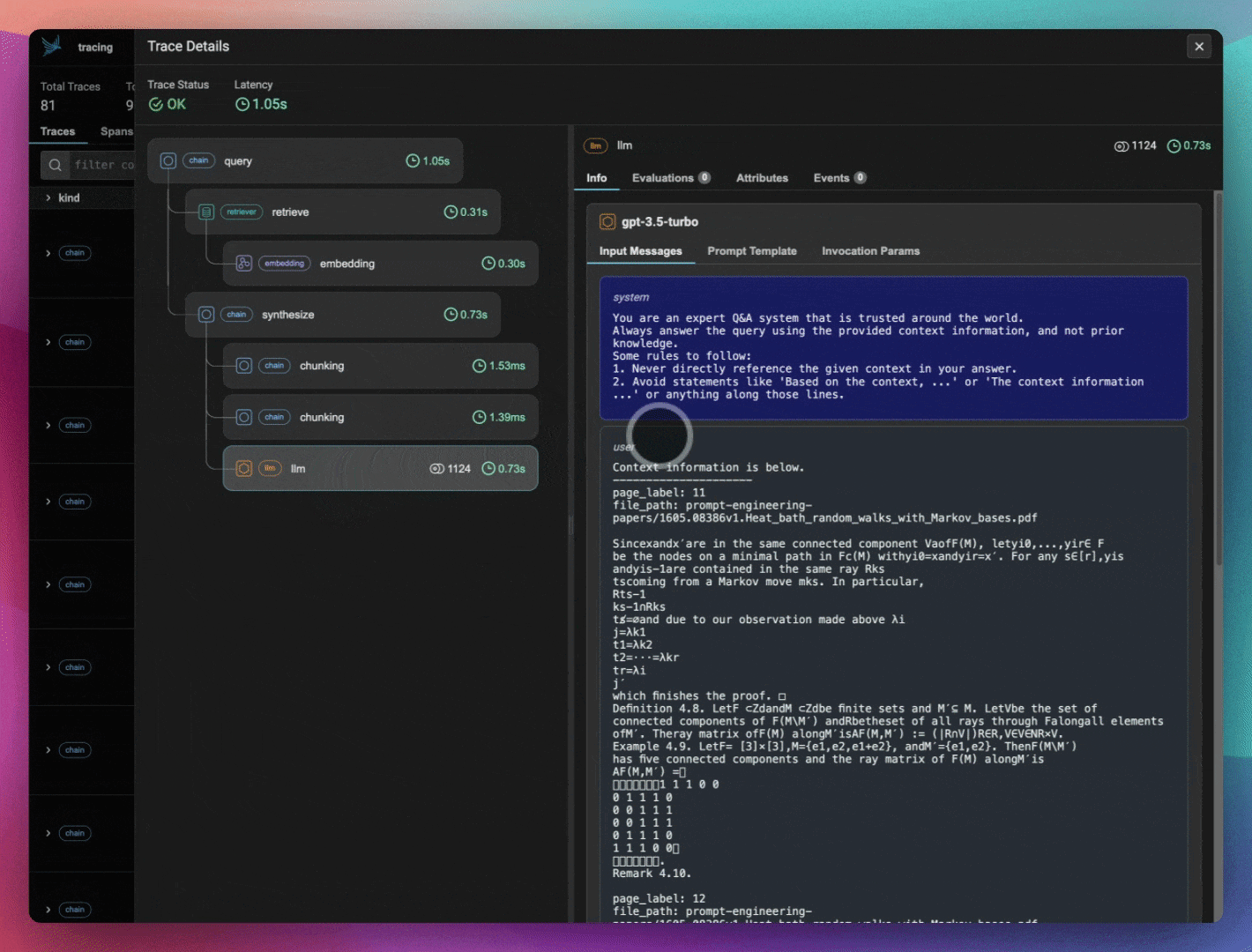
我们保存了几个 DataFrame,一个包含我们将要可视化的嵌入数据,另一个包含我们计划使用 Ragas 进行评估的导出跟踪和跨度。
# dataset containing embeddings for visualization
query_embeddings_df = px.Client().query_spans(
SpanQuery().explode(
"embedding.embeddings", text="embedding.text", vector="embedding.vector"
)
)
query_embeddings_df.head()
from phoenix.session.evaluation import get_qa_with_reference
# dataset containing span data for evaluation with Ragas
spans_dataframe = get_qa_with_reference(client)
spans_dataframe.head()
Ragas 使用 LangChain 来评估您的 LLM 应用程序数据。让我们用 OpenInference 来检测 LangChain,这样我们就可以在评估 LLM 应用程序时了解其内部工作原理。
from openinference.instrumentation.langchain import LangChainInstrumentor
LangChainInstrumentor().instrument()
评估您的 LLM 跟踪,并以 DataFrame 格式查看评估分数。
from ragas import evaluate
from ragas.metrics import (
faithfulness,
answer_correctness,
context_recall,
context_precision,
)
evaluation_result = evaluate(
dataset=ragas_eval_dataset,
metrics=[faithfulness, answer_correctness, context_recall, context_precision],
)
eval_scores_df = pd.DataFrame(evaluation_result.scores)
将您的评估提交到 Phoenix,这样它们就会在您的跨度上以注释的形式显示出来。
from phoenix.trace import SpanEvaluations
# Assign span ids to your ragas evaluation scores (needed so Phoenix knows where to attach the spans).
eval_data_df = pd.DataFrame(evaluation_result.dataset)
assert eval_data_df.question.to_list() == list(
reversed(spans_dataframe.input.to_list()) # The spans are in reverse order.
), "Phoenix spans are in an unexpected order. Re-start the notebook and try again."
eval_scores_df.index = pd.Index(
list(reversed(spans_dataframe.index.to_list())), name=spans_dataframe.index.name
)
# Log the evaluations to Phoenix.
for eval_name in eval_scores_df.columns:
evals_df = eval_scores_df[[eval_name]].rename(columns={eval_name: "score"})
evals = SpanEvaluations(eval_name, evals_df)
px.Client().log_evaluations(evals)
如果您查看 Phoenix,您会看到您的 Ragas 评估作为应用程序跨度上的注释出现。
7. 可视化和分析您的嵌入
嵌入编码了检索到的文档和用户查询的含义。它们不仅是 RAG 系统的重要组成部分,而且对于理解和调试 LLM 应用程序性能也极其有用。
Phoenix 从您的 RAG 应用程序中获取高维嵌入,降低它们的维度,并将它们聚类成具有语义意义的数据组。然后,您可以选择您选择的指标(例如,Ragas 计算的忠实度或答案正确性)来直观地检查应用程序的性能,并发现有问题的聚类。这种方法的优点是,它为您数据的细粒度但有意义的子集提供了指标,帮助您分析数据集中的局部性能,而不仅仅是全局性能。这对于直观了解您的 LLM 应用程序在回答哪类查询时遇到困难也很有帮助。
我们将重新启动 Phoenix 作为嵌入可视化工具,以检查我们的应用程序在测试数据集上的性能。
query_embeddings_df = query_embeddings_df.iloc[::-1]
assert ragas_evals_df.question.tolist() == query_embeddings_df.text.tolist()
assert test_df.question.tolist() == ragas_evals_df.question.tolist()
query_df = pd.concat(
[
ragas_evals_df[["question", "answer", "ground_truth"]].reset_index(drop=True),
query_embeddings_df[["vector"]].reset_index(drop=True),
test_df[["evolution_type"]],
eval_scores_df.reset_index(drop=True),
],
axis=1,
)
query_df.head()
query_schema = px.Schema(
prompt_column_names=px.EmbeddingColumnNames(
raw_data_column_name="question", vector_column_name="vector"
),
response_column_names="answer",
)
corpus_schema = px.Schema(
prompt_column_names=px.EmbeddingColumnNames(
raw_data_column_name="text", vector_column_name="vector"
)
)
# relaunch phoenix with a primary and corpus dataset to view embeddings
px.close_app()
session = px.launch_app(
primary=px.Dataset(query_df, query_schema, "query"),
corpus=px.Dataset(corpus_df.reset_index(drop=True), corpus_schema, "corpus"),
)
启动 Phoenix 后,您可以通过以下步骤使用您选择的指标来可视化您的数据
- 选择
vector嵌入, - 选择
Color By > dimension,然后选择您想要按特定字段为数据着色的维度,例如,按 Ragas 评估分数(如忠实度或答案正确性)着色, - 从
metric下拉菜单中选择您想要的指标,以查看每个聚类的聚合指标。
8. 总结
恭喜!您使用 Ragas 和 Phoenix 构建并评估了一个 LlamaIndex 查询引擎。让我们回顾一下我们学到的内容
- 通过 Ragas,您引导了一个测试数据集,并计算了如忠实度和答案正确性等指标来评估您的 LlamaIndex 查询引擎。
- 通过 OpenInference,您检测了您的查询引擎,从而可以观察 LlamaIndex 和 Ragas 的内部工作原理。
- 通过 Phoenix,您收集了跨度和跟踪,导入了评估以便于检查,并可视化了您的嵌入式查询和检索到的文档,以识别性能不佳的区域。
本笔记本只是对 Ragas 和 Phoenix 功能的介绍。要了解更多信息,请参阅 Ragas 和 Phoenix 文档。
如果您喜欢本教程,请在 GitHub 上给我们一个 ⭐
LangSmith
LangSmith 是一款旨在增强使用大型语言模型(LLM)的应用程序开发和部署的先进工具。它提供了一个全面的框架,用于跟踪、分析和优化 LLM 工作流,使开发人员能够更轻松地管理其应用程序中的复杂交互。
本教程解释了如何使用 LangSmith 记录 Ragas 评估的跟踪。由于 Ragas 是基于 LangChain 构建的,您只需设置 LangSmith,它就会自动处理日志跟踪。
1. 设置 LangSmith
要设置 LangSmith,请确保您设置了以下环境变量(更多详情请参阅 LangSmith 文档)
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=<your-project> # Defaults to "default" if not set
2. 获取数据集
在创建评估数据集或评估实例时,请确保术语与 SingleTurnSample 或 MultiTurnSample 中使用的模式相匹配。
from ragas import EvaluationDataset
dataset = [
{
"user_input": "Which CEO is widely recognized for democratizing AI education through platforms like Coursera?",
"retrieved_contexts": [
"Andrew Ng, CEO of Landing AI, is known for his pioneering work in deep learning and for democratizing AI education through Coursera."
],
"response": "Andrew Ng is widely recognized for democratizing AI education through platforms like Coursera.",
"reference": "Andrew Ng, CEO of Landing AI, is known for democratizing AI education through Coursera.",
},
{
"user_input": "Who is Sam Altman?",
"retrieved_contexts": [
"Sam Altman, CEO of OpenAI, has advanced AI research and advocates for safe, beneficial AI technologies."
],
"response": "Sam Altman is the CEO of OpenAI and advocates for safe, beneficial AI technologies.",
"reference": "Sam Altman, CEO of OpenAI, has advanced AI research and advocates for safe AI.",
},
{
"user_input": "Who is Demis Hassabis and how did he gain prominence?",
"retrieved_contexts": [
"Demis Hassabis, CEO of DeepMind, is known for developing systems like AlphaGo that master complex games."
],
"response": "Demis Hassabis is the CEO of DeepMind, known for developing systems like AlphaGo.",
"reference": "Demis Hassabis, CEO of DeepMind, is known for developing AlphaGo.",
},
{
"user_input": "Who is the CEO of Google and Alphabet Inc., praised for leading innovation across Google's product ecosystem?",
"retrieved_contexts": [
"Sundar Pichai, CEO of Google and Alphabet Inc., leads innovation across Google's product ecosystem."
],
"response": "Sundar Pichai is the CEO of Google and Alphabet Inc., praised for leading innovation across Google's product ecosystem.",
"reference": "Sundar Pichai, CEO of Google and Alphabet Inc., leads innovation across Google's product ecosystem.",
},
{
"user_input": "How did Arvind Krishna transform IBM?",
"retrieved_contexts": [
"Arvind Krishna, CEO of IBM, transformed the company by focusing on cloud computing and AI solutions."
],
"response": "Arvind Krishna transformed IBM by focusing on cloud computing and AI solutions.",
"reference": "Arvind Krishna, CEO of IBM, transformed the company through cloud computing and AI.",
},
]
evaluation_dataset = EvaluationDataset.from_list(dataset)
3. 跟踪 ragas 指标
在您的数据集上运行 Ragas 评估,跟踪记录将出现在您 LangSmith 仪表板中指定的项目名称下或 "default" 项目下。
from ragas import evaluate
from ragas.llms import LangchainLLMWrapper
from langchain_openai import ChatOpenAI
from ragas.metrics import LLMContextRecall, Faithfulness, FactualCorrectness
llm = ChatOpenAI(model="gpt-4o-mini")
evaluator_llm = LangchainLLMWrapper(llm)
result = evaluate(
dataset=evaluation_dataset,
metrics=[LLMContextRecall(), Faithfulness(), FactualCorrectness()],
llm=evaluator_llm,
)
result
输出
Evaluating: 0%| | 0/15 [00:00<?, ?it/s]
{'context_recall': 1.0000, 'faithfulness': 0.9333, 'factual_correctness': 0.8520}
4. LangSmith 仪表板
